
Over the last few months the UChicago team and I have been focusing on detecting credit card fraud utilizing Markov-chain based models and streaming transaction data. One of the main issues that we ran into developing our modeling strategy was that our initial results were based on small-ish sized data sets (~10GB), and that those results didn’t necessarily reflect performance at “Big Data” scale. We decided to increase the data set size to ~250GB (not really “Big Data”, but “Big Data”-ish enough for this purpose) and evaluate our model / process performance. One of the more effective changes we incorporated as a result was moving from .csv to parquet file format for our data set, and we saw significant and immediate improvement in our model training performance.
Somewhat in parallel to that work I’d been following the development of PrestoDB, as its ability to connect into RDMBS territory as well as integrating with data on HDFS really appealed to me. I’d also never really been a fan of the speed (or lack thereof) of map-reduce, so it sounded pretty interesting as a potential solution to some real-world big data issues (namely the difference between what IT management was sold by vendors as insanely quick Hadoop performance, and what an actual Hadoop implementation ends up providing). Once I found out PrestoDB had an existing Tableau connector as well as a MongoDB connector in the works, I immediately put it on my list of things to play around with.
A few weeks ago I ran across an article where Netflix had discussed a key concept of their Big Data solution, and that was running PrestoDB against their DW which was essentially parquet files on a S3 data store. The fact that they were using S3 instead of HDFS kind of blew my mind, and I was pretty dubious. Digging into their reasoning a bit more closely I found it really hard to argue with, and I started getting excited about the idea myself. Higher availability and a massive boost in flexibility with respect to deploying various clusters, making copies of their data, etc.. would solve a number of pain points I’d experienced with Hadoop and HDFS. If you’ve ever tried to get a really large data set off of HDFS, you’ll know what a pain that can be. With S3 not only are their availability and capacity issues taken care of, but the data is easily accessible in numerous different ways.
I think my favorite aspect of the S3 concept was the idea of spinning up AWS EMR clusters at will, or modifying existing clusters. The data is not actually on the cluster, so there’s no worries there at all. Need a new QA environment? Spin it up with the click of a button. Dev data is old and needs refreshing? Copy the production S3 data to a new bucket and point to it. Not to mention S3 has built in versioning and options for encryption, and they’ve made serious strides in the development of EMRFS, especially with respect to their file system consistency.
So seeing what Netflix did and how impressed I was with that solution, I decided the time had come to dig into PrestoDB, and at the same time understand just how feasible S3 would be instead of using HDFS. I was also curious to see if the gains I’d seen going from CSV to parquet on HDFS would be marginalized by S3.
Thankfully, AWS makes it easy these days to test all of this. I created a test EMR cluster (4.1.0, don’t use 4.2.0 to try this, there’s a bug in the AWS emrfs command line utility currently) that consisted of 11 nodes. 1 name node, 10 data notes, all c3.8xlarge.

I decided to explore a few scenarios that included testing Hive vs PrestoDB for both CSV and Parquet format. Due to previously mentioned anomaly detection work at UChicago I had a medium-sized (~150GB / 500MM rows) data set already sitting on S3 that would work well. I loaded the S3 stored CSV data into Hive as an external table. After I created that table, I created another external table using S3 storage, but this time I used the parquet format. I’m including a screen-cap of a portion of the data below so you can get a feel for what it looks like. Essentially it’s 3 year’s worth of 150,000 customer’s (synthetically generated) credit card transactions (both legitimate and fraudulent).

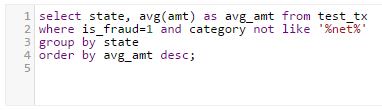
As far as queries, I wrote 3 to serve as the actual test set that I felt might fit some more general end-user OLAP style queries. The first is a simple aggregate looking for the average amount of fraudulent credit card transactions for a user living in Chicago. The second query looked for the average amount of fraudulent transactions per state, and then sorted the results in descending order (aggregate operation, group by, and a small amount of sorting). The final query featured a full-text scan of a field called ‘category’. Each transaction is grouped into the type of category the merchant belongs to (grocery, jewelry, etc.. and there are online retailers by category as well, identified by a _net suffix). I filtered out any online transactions (containing ‘_net’ in the category field) by appending a ‘category NOT LIKE ‘%net%’ predicate to the where clause. I thought this was interesting because this would force traditional RDBMS into a full table scan (full-text indexes not-withstanding) so I was curious to see what kind of performance impact it might have, given that we’re using traditional SQL statements.
The text of the test queries are below. I’ll refer to these as the ‘simple query’, ‘complex query #1’, and ‘complex query #2’. All tests were run multiple times and the below results are averages of the execution times. Steps were taken (namely restarting prestodb-server quite often) to avoid any chance of query caching. As this cluster was created solely for these tests, workloads were run independently and there was no other resource contention.


The first test was Hive vs PrestoDB against the S3-based CSV data using the simple query. Now before I get to the results, I want to note that something weird was happening with PrestoDB right out of the box, as it was MUCH slower than even Hive / MR for this simple query. It turns out that it’s still in ‘sandbox’ mode over at AWS so some modification of the jvm.config file was needed. Below is the initial JVM and afterward are my modifications. There was an increase in memory as well as a change to garbage collection.
Original jvm.config

updated jvm.config

Once the JVM issues were sorted out, performance seemed to be in-line with my expectations. As you can see, parquet had a huge performance jump in both scenarios (Hive vs PrestoDB), but even more than that, PrestoDB on parquet is just getting insane with its execution time.

Moving on to the more complex queries (where strangely enough, it seems the less complex of the two took the longest to execute across the board), we see similar patterns. Parquet gives quite the boost in performance even for map-reduce, but PrestoDB on parquet is just hands-down the winner.


Considering this was all on S3 and there was no HDFS involved in the equation at all, I’m really starting to get on board with S3 as a suitable HDFS replacement. I think it’s a fantastic option, assuming your organizational needs or requirements allow it. Naturally HDFS will be a bit faster, but in my opinion, the flexibility and increased availability of S3 really are worth the minor hit in performance.
As far as PrestoDB, I’m definitely impressed. It delivered very well, and I even tested out the Airpal web interface which is a decent replacement for something like the Hive editor in Hue or Ambari (though I’m not 100% sure how well it compares as far as authentication options which is an important aspect if you’re looking at enterprise-wide deployment). If you’re worried about vendor support worry no more. Teradata has started providing enterprise support for PrestoDB.
In the future I plan on seeing how Impala and perhaps Drill stack up against PrestoDB on S3, so if you were hoping for some comparisons on that front stay tuned.