

Local LLMs - Getting Started with LLaMa on AWS EC2
As the world of AI continues to evolve, large language models (LLMs) have become increasingly popular. These models offer powerful capabilities for tasks such as text generation, summarization, translation, and more. In this blog post, we’re going to walk through running your own copy of a local, open LLM on the cloud (in this case AWS). Before that though, we’ll explore the benefits of running local LLMs, discuss some of the most prominent open-source models available, and introduce you to Hugging Face, a key player in the LLM research community.
Why Use Local LLMs?
Running LLMs locally offers several advantages, including data privacy and security, reduced latency, customization, and offline availability. By keeping your data within your own infrastructure, you minimize the risk of data breaches and unauthorized access. Local LLMs also eliminate the latency associated with remote servers, leading to faster API response times as there’s no need to transit the internet. Additionally, running LLMs locally allows for fine-tuning and modification according to your specific needs (after all, what good is a model if it doesn’t have the information you need it to know). Finally, local LLMs can be used without an internet connection, making them suitable for embedded and edge applications with limited or no connectivity.
Open-Source LLMs for Local Use
Most of the current activity (and this changes very quickly, all of this work is bleeding edge) has been around Facebook / Meta’s LLaMa. Originally, access to the model was restricted for academic work or with Meta’s approval, but the weights were “leaked”. Whether or not that was done on purpose, or an act of rebellion is up for debate, but one thing is for sure, it caused work around training and fine-tuning LLM’s to accelerate exponentially. Papers are being released almost daily and being only a few weeks out of date can feel like years in most other areas of research. The pace here is beyond even what we saw with RNN and CNN models 5-10 years ago, it’s really astounding.
Since the weights were leaked, there’s has been an explosion of work done to fine-tuned additional models for various purposes, even the fine-tuning process itself has been revolutionized with quantitzation and concepts like QLoRA. Keeping track of all of this is hard, but there’s a key player here that makes this a bit easier, and that is the GitHub (and more!) for the LLM age, HuggingFace.
Hugging Face and LLM Research
Hugging Face (HF) is platform that allows users to share, discover, and collaborate on AI models. It hosts thousands of pre-trained models, which can be fine-tuned for specific tasks or used as-is. HF also encourages collaboration, as users can contribute their models and improvements to existing ones. There is a fantastic repository of datasets as well, all easily filterable by task, size, language and more. The “Spaces” section of the website is an area that users can use to build and share apps and implementations of models for others to experiment with. HF has really become the GitHub for AI, so if you ever want to see what’s new in the LLM world, Hugging Face should be one of your first stops.
Getting Started - Flying LLaMa (or models on the cloud with AWS)
There are two components that we’re going to need to focus on in order to get our model into a usable form like one would expect with ChatGPT or others. The first is the model itself, and for this example we’re going to be using a model called Minotaur from the OpenAccess AI Collective (who have also created some amazing tools in this space such as axolotl). This model was chosen because it was fine-tuned on completely open datasets and should be reproducible. You’ll find intellectual property can be a landmine topic in generative AI, and when possible, I think it’s best to stick with models that are trained on open sources.
The second component that we’ll need is a UI so that we can interact with the model. We’re going to take a web-based approach with this, but you could also choose to use an option like llama.cpp for text-based environments. For our UI, we’re going to use a tool called text-generation-webui.
Before any of this though, we’ll need our infrastructure. You can certainly follow along if you have a local linux machine configured with CUDA and a supported GPU, but we’re going to use AWS for this example. Now, before I get a bunch of comments on using AWS, there are other services that can be cheaper and are targeted specifically for these use cases. runpod.io is one example. I may write another similar post using runpod, but AWS has been around for so long that many people are very familiar with it and when trying something new, reducing the variables in play can help. That being said, there is nothing provider specific here, you should be able to follow the basic steps assuming you have a compatible OS, configured for scientific computing with conda, pytroch and CUDA.
A few final notes. You should be familiar with launching an ec2 instance from the console, as well as configuring a security group, and using SSH to connect to your ec2 instance. If you need help with that, this is a good starting point.
OK, let’s jump into this!
Start on the AWS Console and launch an EC2 instance..
When it comes to configuring the OS, search the AMI list for “deep” to locate the latest preconfigured deep learning AMI.
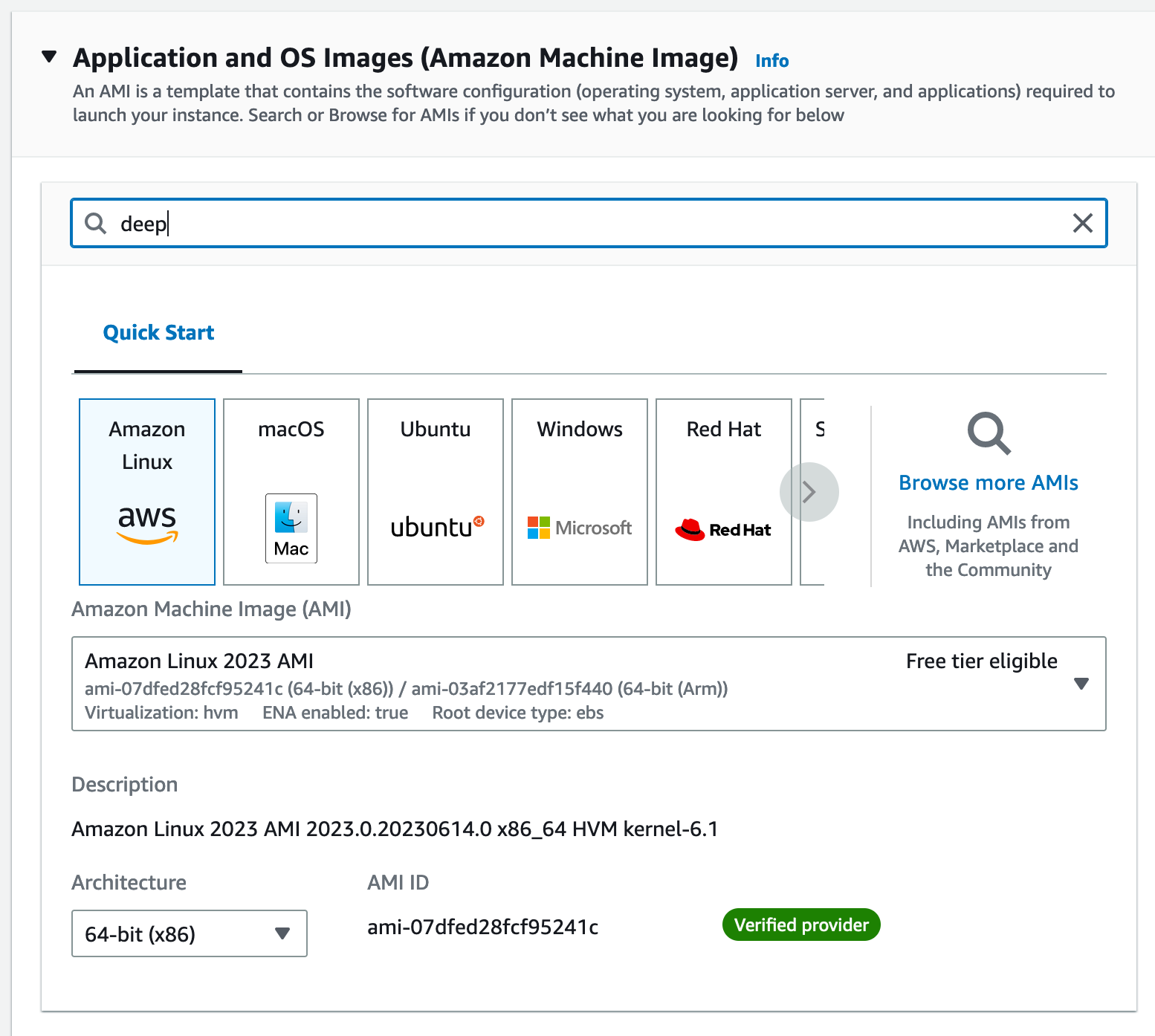
In my case, I chose Deep Learning AMI GPU PyTorch 2.0.1 (Ubuntu 20.04) 20230613 which had an AMI ID value of ami-026cbdd44856445d0 . Keep in mind that ami identifiers are region specific, this is US-WEST-2 / Oregon, and will likely be superseded by the time this is published.
Choose p3.2xlarge instance type to start. There are a variety of GPU instances AWS and others offer, but typically the main constraint will be GPU memory. The p3.2xlarge offers a GPU with 16GB of GPU memory which is on the low end, but sufficient for our needs here.
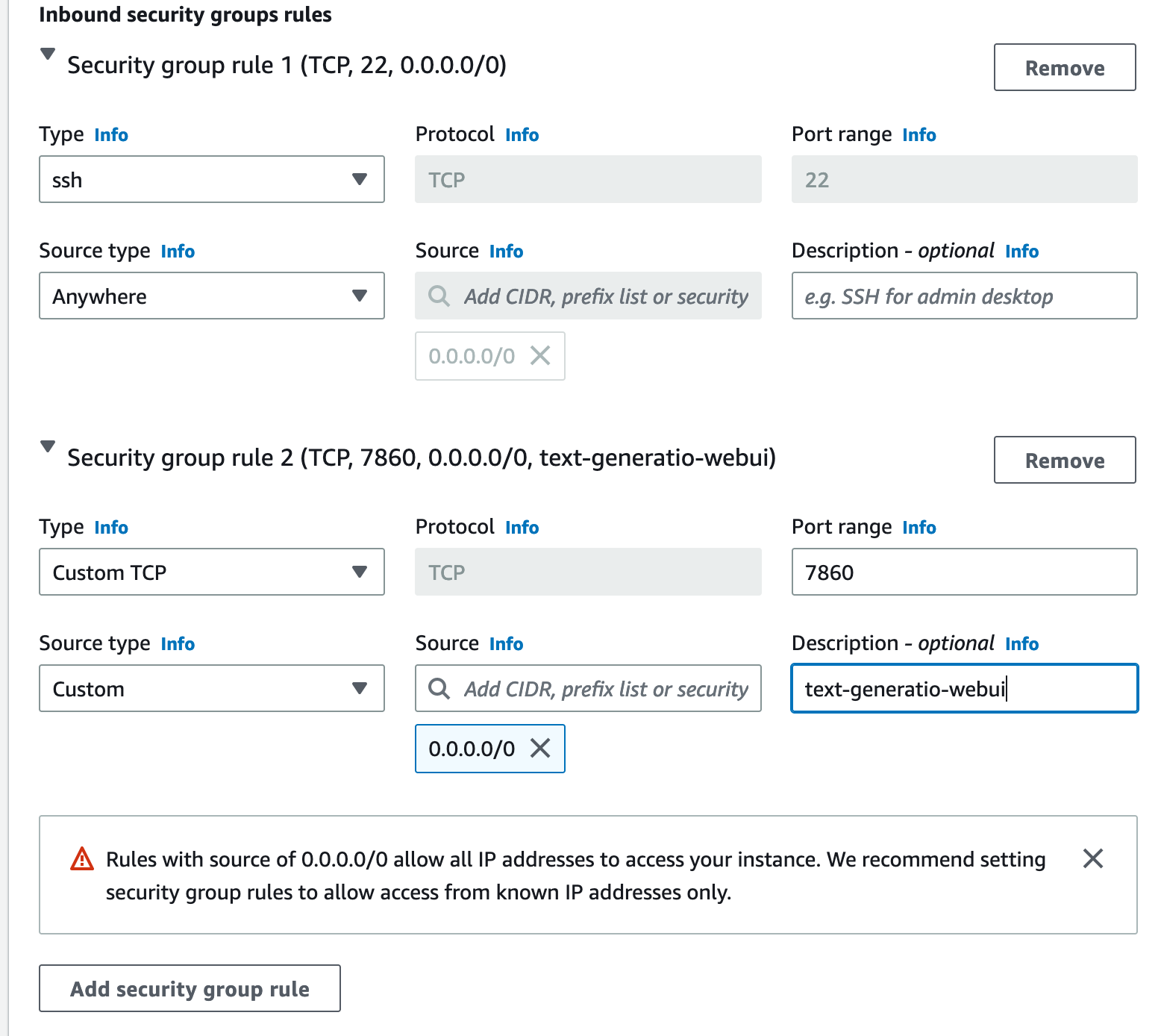
When you are configuring your EC2 instance, you’ll need to make sure the security group will allow traffic on TCP/22 (SSH) , and TCP/7860 (the port the text generation UI will run on). You may need to edit the networking section when launching the instance to do this, or you can do it after launching the instance as well. I’ll leave it to you to determine which CIDR range you want to use, but to allow traffic from anywhere you would use ‘0.0.0.0/0’ (this is a bad security practice).
Update storage for the root volume to 250GB to allow for downloaded models.

Launch your instance!
Once your instance has been configured and is available, SSH into the instance and enter the following commands at your terminal prompt to configure the environment. This may take 5-10 minutes to finish.
conda update -y -n base -c conda-forge conda
conda create -y -n textgen python=3.10.9
conda init bash
source .bashrc
conda activate textgen
yes | pip3 install torch torchvision torchaudioYou should see installation text progressing at this point.
Once the configuration has finished, let’s install the text-generation-webui.
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
yes | pip install -r requirements.txtAt this point you can launch web console
python server.py --listenNote that the “listen” option allows the web UI to bind to a non-loopback IP address such as your public or private IP from AWS. Without this, you won’t be able to access your UI. Also note that unless you restrict IP traffic, anyone in the world can visit this page. You could put this behind a reverse proxy with basic auth if you wanted to leave it running, but I would suggest stopping the service when you are not using the UI.
Assuming all was successful, and you configured your security groups appropriately, you should be able to access the text-generation-webui at http://your-ec2-public-ip:7860
Now it’s time to install our model. At the top of the UI, there are a series of tabs.
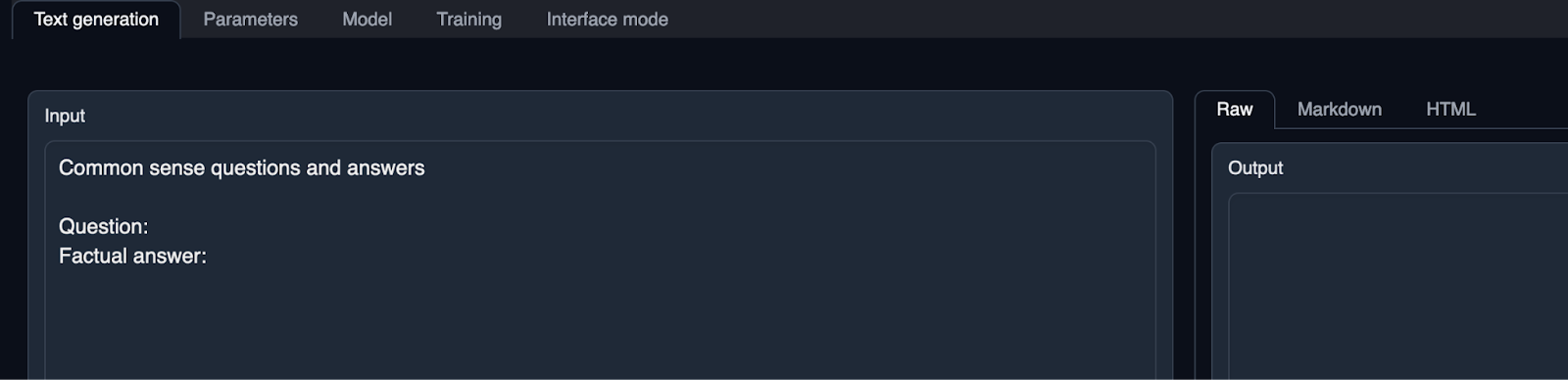
On the model tab, in the “Download Custom Model or LoRA” text box enter
TheBloke/minotaur-15B-GPTQ
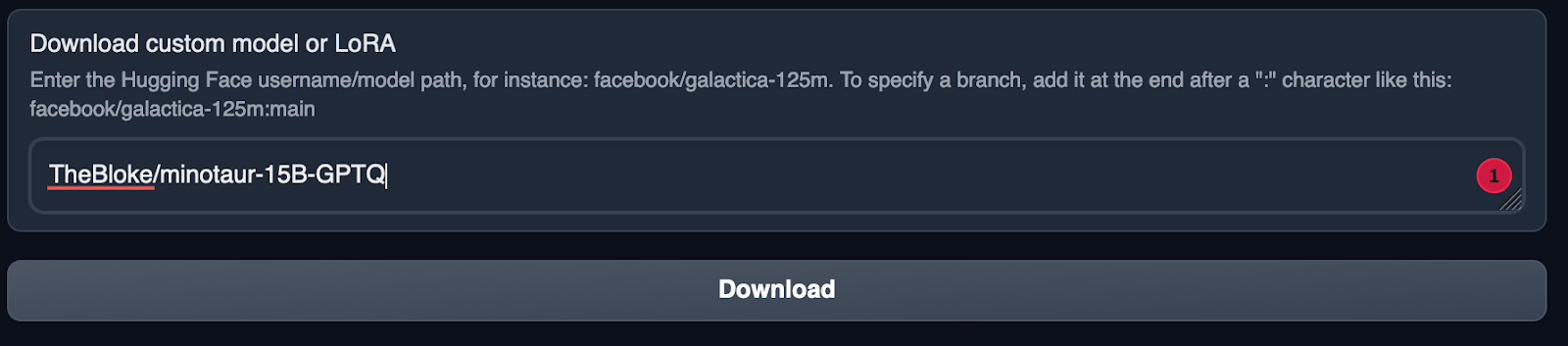
Click Download.
The model will start downloading. Once it’s finished it will say “Done”
In the top left, click the refresh icon next to Model. (not the “reload” button!)
In the Model dropdown, choose the model you just downloaded: minotaur-15B-GPTQ
The model will automatically load, and is now ready for use!
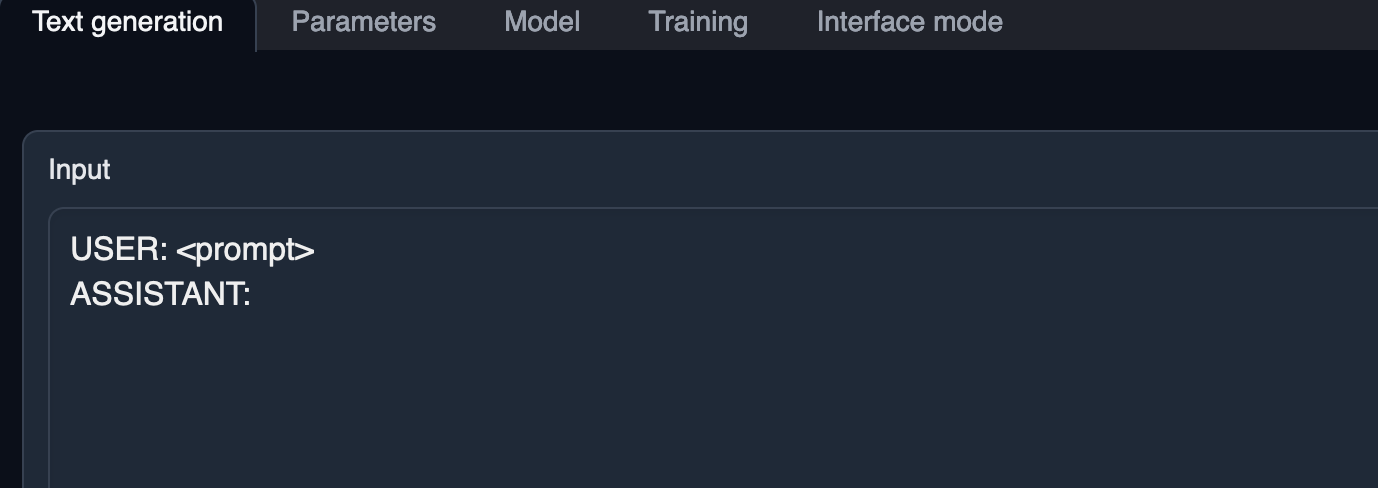
Once you’re ready, click the Text Generation tab and enter a prompt to get started!
For minotaur - I suggest using the prompt configured as below. Replace

That’s all there is to it! We’ve downloaded an LLaMa based LLM model, configured a web UI to work with it and done so using cloud resources at AWS. Not too hard, right?
Things can get very interesting when you expand these capabilities to include using a model that has been fine-tuned to answer questions about your own, proprietary data. How you can easily do that with llama_index will be in the next blog post, when we teach our local model to read a book of our choosing and then answer questions!
If you’re interested in learning more stay tuned for continuing, hands on walk-throughs in the AI and LLM space. If you can’t wait, surf on over and read the latest from Fred Bliss at Blissintersect who really has the pulse of major devleopments in this area.
Finally, if you’re interested in writing and sharing your thoughts on this topic, I’ve established Quicksail.ai as an open-source research collective to explore applied uses of Data, AI and LLM’s. We’re always looking to network with passionate and like-minded for people interested in exploring these topics through blogging or POC’s with open source technologies.